【代码随想录】贪心算法
贪心算法基础
贪心的本质是选择每一阶段的局部最优,从而达到全局最优。
说实话贪心算法并没有固定的套路。
如何验证可不可以用贪心算法呢?
最好用的策略就是举反例,如果想不到反例,那么就试一试贪心吧。
一般数学证明有如下两种方法:
- 数学归纳法
- 反证法
看教课书上讲解贪心可以是一堆公式,估计大家连看都不想看,所以数学证明就不在我要讲解的范围内了,大家感兴趣可以自行查找资料。
面试中基本不会让面试者现场证明贪心的合理性,代码写出来跑过测试用例即可,或者自己能自圆其说理由就行了。
刷题或者面试的时候,手动模拟一下感觉可以局部最优推出整体最优,而且想不到反例,那么就试一试贪心。
贪心算法一般分为如下四步:
- 将问题分解为若干个子问题
- 找出适合的贪心策略
- 求解每一个子问题的最优解
- 将局部最优解堆叠成全局最优解
分发饼干
题目:455
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。
对每个孩子 i,都有一个胃口值 g[i],这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j,都有一个尺寸 s[j] 。如果 s[j] >= g[i],我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
思路:对于孩子 i,从饼干中找到一个刚刚满足的他的饼干大小。
将二者都排序,然后遍历饼干,小饼干先满足小胃口的。
局部最优:大饼干喂给胃口大的,小饼干喂给胃口小的
全局最优:喂饱尽可能多的小孩
1 | class Solution { |
时间复杂度 O (nlogn);空间复杂度 O (1)
摆动序列
题目:376
如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为 摆动序列 。第一个差(如果存在的话)可能是正数或负数。仅有一个元素或者含两个不等元素的序列也视作摆动序列。
- 例如,
[1, 7, 4, 9, 2, 5]是一个 摆动序列 ,因为差值(6, -3, 5, -7, 3)是正负交替出现的。 - 相反,
[1, 4, 7, 2, 5]和[1, 7, 4, 5, 5]不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
子序列 可以通过从原始序列中删除一些(也可以不删除)元素来获得,剩下的元素保持其原始顺序。
给你一个整数数组 nums ,返回 nums 中作为 摆动序列 的 最长子序列的长度 。
解法 1:贪心算法:局部最优:删除单调递增的元素,尽量使得出现波峰和波谷
整体最优:波峰和波谷最多

这样最基本的计算增加子序列长度的条件就是:当前一个差值和后一个差值符号相反时就可以增加
另外需要考虑的是:当出现相等的情况时,即
情况一:上下坡中有平坡
例如 [1,2,2,2,1] 这样的数组,如图:

它的摇摆序列长度是多少呢? 其实是长度是 3,也就是我们在删除的时候 要不删除左面的三个 2,要不就删除右边的三个 2。
如图,可以统一规则,删除左边的三个 2:

在图中,当 i 指向第一个 2 的时候,prediff > 0 && curdiff = 0 ,当 i 指向最后一个 2 的时候 prediff = 0 && curdiff < 0。
如果我们采用,删左面三个 2 的规则,那么 当 prediff = 0 && curdiff < 0 也要记录一个峰值,因为他是把之前相同的元素都删掉留下的峰值。
所以我们记录峰值的条件应该是: (preDiff <= 0 && curDiff > 0) || (preDiff >= 0 && curDiff < 0),为什么这里允许 prediff == 0 ,就是为了 上面我说的这种情况。
另外需要考虑的是计算两个差值需要至少三个数,当数组只有两个数时应该如何处理:
情况二:单独处理两个元素
可以直接将两个元素的数组列出来,也可以加入到上面的情况中。
例如序列 [2,5],如果靠统计差值来计算峰值个数就需要考虑数组最左面和最右面的特殊情况。
因为我们在计算 prediff(nums [i] - nums [i-1]) 和 curdiff(nums [i+1] - nums [i])的时候,至少需要三个数字才能计算,而数组只有两个数字。
这里我们可以写死,就是 如果只有两个元素,且元素不同,那么结果为 2。
不写死的话,如何和我们的判断规则结合在一起呢?
可以假设,数组最前面还有一个数字,那这个数字应该是什么呢?
之前我们在 讨论 情况一:相同数字连续 的时候, prediff = 0 ,curdiff <0 或者>0 也记为波谷。
那么为了规则统一,针对序列 [2,5],可以假设为 [2,2,5],这样它就有坡度了即 preDiff = 0,如图:
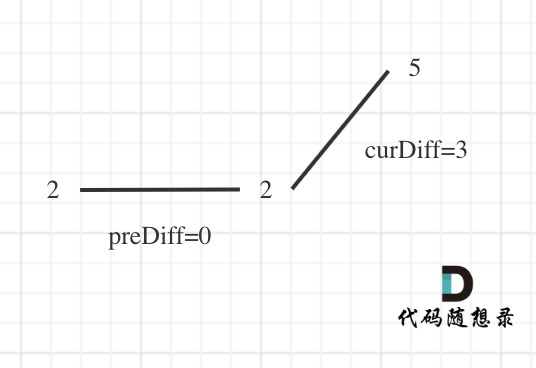
针对以上情形,result 初始为 1(默认最右面有一个峰值),此时 curDiff > 0 && preDiff <= 0,那么 result++(计算了左面的峰值),最后得到的 result 就是 2(峰值个数为 2 即摆动序列长度为 2)
情况三:单调坡度有平坡
在版本一中,我们忽略了一种情况,即 如果在一个单调坡度上有平坡,例如 [1,2,2,2,3,4],如图:

图中,我们可以看出,版本一的代码在三个地方记录峰值,但其实结果因为是 2,因为 单调中的平坡 不能算峰值(即摆动)。
之所以版本一会出问题,是因为我们实时更新了 prediff。
那么我们应该什么时候更新 prediff 呢?
我们只需要在 这个坡度 摆动变化的时候,更新 prediff 就行,这样 prediff 在 单调区间有平坡的时候 就不会发生变化,造成我们的误判。
思路 2:贪心:这里的贪心是计算出所有差值,要求差值必须是一个大于 0,下一个小于 0. 同样是能够使得波峰和波谷最多。
分别计算以正数和负数差值开始的序列,取最长的最为答案。
另外需要注意,如果找不到正数和负数差,说明全都是相等元素。
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (n)
思路 3:动态规划
1. 定义 dp 数组
如果要以下标为 i 的元素作为子序列的结尾,需要记录这个元素是波峰还是波谷。因此定义 dp [i][0] 表示 [0, i] 中以 i 作为波峰元素的最长摆动序列长度;dp [i][1] 表示 [0, i] 中以 i 作为波谷元素的最长摆动子序列
2. 递推公式:
考虑第 i 个元素,
dp [i][0] 表示以第 i 个元素作为波谷,因此需要找到前面的某个波峰,接在后面作为波谷,因此 dp [i][0] = max (dp [i][0], dp [j][1] + 1),其中 j 遍历 [0, i-1],并且 nums [j] > nums [i]
dp [i][1] 表示以第 i 个元素作为波峰,因此需要找到前面的某个波谷,接在后面作为波峰,因此 dp [i][1] = max (dp [i][1], dp [j][0] + 1),其中 j 遍历 [0, i-1],并且 nums [j] < nums [i]
3. 初始化:
dp [0][0] 和 dp [0][1] 表示以第一个元素作为波峰或者波谷,因此长度为 1。对于每个元素来说,都可以以自己作为波峰或者波谷,因此都初始化为 1。
4. 遍历顺序:
从左到右
1 | class Solution { |
最大子序和
题目:53
思路 1:暴力破解法:元素下标从第一个元素到最后一个元素,分为作为子序列起始元素,遍历起始元素后面的元素,记录最大子序列和。
思路 2:贪心算法:局部最优:当前 “连续和” 为负数的时候立刻放弃,从下一个元素重新计算 “连续和”,因为负数加上下一个元素 “连续和” 只会越来越小。
全局最优:选取最大 “连续和”
局部最优的情况下,并记录最大的 “连续和”,可以推出全局最优。
我的理解:可以将整个序列看成是多个子序列,将多个子序列进行组合成一个更大的子序列,那么只有当子序列之和为正时合并才会使得组合而成的子序列的值变大。
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (1)
思路 3:动态规划,因为是子数组问题,可以考虑使用动态规划解决原问题与子问题。
1. 定义 dp 数组:
dp [i] 表示 [0, i] 下标内以下标 i 结尾的最大的连续子数组和,这样暴力法中连续子数组的右端就被确定下来了。
2. 确定递推公式:
要么 dp [i - 1] + nums [i],要么只能是 nums [i]。
因此递推公式就是 max (dp [i - 1] + nums [i], nums [i])
3. 初始化:
dp [0] 只能是第一个元素
4. 遍历顺序:
从前向后
5. 例子:
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (n),但是由于只依赖与前面一个元素,所以可以降到 O (1)
总结
贪心的本质是选择每一阶段的局部最优,从而达到全局最优。
饼干分发:小饼干尽量满足胃口小的
最长摇摆序列:保持相邻两个元素波动,即删除单调坡度上的点
最大子序列和:将序列看成是多个子序列,只有子序列和为正才能参与组合,子序列和为负只会拉低组合序列的和的大小。
买卖股票的最佳时机 II
题目:122
思路 1:买入股票之后,只要股票价格在涨,就不卖出;当股票价格下跌时就立即卖出。
特殊情况是整个序列都是递增的,不会出现下降,这个时候需要判断是否为最后一个元素
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (1)
思路 2:贪心算法:如果想到其实最终利润是可以分解的,那么本题就很容易了!
如何分解呢?
假如第 0 天买入,第 3 天卖出,那么利润为:prices [3] - prices [0]。
相当于 (prices [3] - prices [2]) + (prices [2] - prices [1]) + (prices [1] - prices [0])。
此时就是把利润分解为每天为单位的维度,而不是从 0 天到第 3 天整体去考虑!
那么根据 prices 可以得到每天的利润序列:(prices [i] - prices [i - 1])…..(prices [1] - prices [0])。
如图:

局部最优:收集每天的正利润,全局最优:求得最大利润。
局部最优可以推出全局最优,找不出反例,试一试贪心
1 | class Solution { |
贪心思路与思路 1 原理上是一样的,都是累积大于 0 的利润,思路 1 是累积一段,贪心是累积每一天。
思路 3:动态规划:
1. 定义 dp 数组:
每一天分为持有和不持有股票的状态,因此 dp [i][0] 表示第 i 天持有股票的最大利润;dp [i][1] 表示第 i 天上不持有股票的最大利润
2. 递推公式:
dp [i][0]:第 i 天持有股票,由于同时只能持有一个股票,所以要么前一天不持有股票, dp [i - 1][1] - prices [i]; 要么前一天也持有股票,dp [i][0] = dp [i - 1][1];因此 dp [i][0] = max (dp [i - 1][1] - prices [i], dp [i - 1][1])
dp [i][1]:第 i 天不持有股票,那么要么前一天也不持有股票,dp [i-1][1];要么前一天持有股票,然后今天卖出,dp [i-1][0] + prices [i]。因此 dp [i][1] = max (dp [i-1][1], dp [i-1][0] + prices [i])
3. 初始化:
第 0 天,持有股票为 - prices [i];不持有股票为 0
4. 遍历顺序:
从前向后
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (n),因为每个元素只依赖于前者,所以可以优化至 O (1)
跳跃游戏
题目:55
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
思路 1:贪心算法
每次可以跳跃的最大距离是 nums [i],这表示下一步可以走的距离是 [i+1, i+nums [i]],如果 nums [i] 为 0,表示永远不可能到达重点。
局部最优:跳跃到下一步最大距离最大的位置,这样下一次可供选择的跳跃点更多,这里注意应该是覆盖范围更大。
整体最优:所有的覆盖范围累加如果能够超越边界就可以跳出去。

1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (1)
思路 2:贪心
每次走下一步时,挑选可选范围中走的更远的一步
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (1)
跳跃游戏 II
题目:45
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
0 <= j <= nums[i]i + j < n
返回到达 nums[n - 1] 的最小跳跃次数。生成的测试用例可以到达 nums[n - 1]。
思路 1:每一步尽可能的多走,但是不能有多远就跳多远,因为这样就不能确定下一步能够到达哪里。
注意覆盖范围内是一步可以跳到的,因此更新下一步的覆盖范围时也是尽可能使得下一步的覆盖范围达到最大。
总体思路是:计算当前可以到达的最大范围,这是一步可以到达的范围;那么然后比较这些范围内下一步可以到达的范围,选择下一步最大范围的跳,这样能够保证以最小步数来扩充范围。跳跃之后判断点是否超过终点,超过终点就结束。
这里需要统计两个覆盖范围,当前这一步的最大覆盖和下一步最大覆盖。
如果移动下标达到了当前这一步的最大覆盖最远距离了,还没有到终点的话,那么就必须再走一步来增加覆盖范围,直到覆盖范围覆盖了终点。
如图:

从图中可以看出来,就是移动下标达到了当前覆盖的最远距离下标时,步数就要加一,来增加覆盖距离。最后的步数就是最少步数。
这里还是有个特殊情况需要考虑,当移动下标达到了当前覆盖的最远距离下标时
- 如果当前覆盖最远距离下标不是是集合终点,步数就加一,还需要继续走。
- 如果当前覆盖最远距离下标就是是集合终点,步数不用加一,因为不能再往后走了。
1 | class Solution { |
时间复杂度 O (n),每个元素最多遍历一次;空间复杂度 O (1)
K 次取反后最大化的数组和
题目:1005
给你一个整数数组 nums 和一个整数 k ,按以下方法修改该数组:
- 选择某个下标
i并将nums[i]替换为-nums[i]。
重复这个过程恰好 k 次。可以多次选择同一个下标 i 。
以这种方式修改数组后,返回数组 可能的最大和 。
思路 1:
设负数个数为 neg,则首先应该把负数变成正数才能使得和最大,所以整体思路为:
如果 neg 大于等于 k:那么把所有的负数变成正数就可以;
如果 neg 小于 k:判断是否存在 0:如果存在 0,那么剩下的次数全变化 0 即可;否则接着判断剩下次数的奇偶:如果是偶数,那么可以将一个正数来回变化偶数次,不影响最后结果;如果是奇数,那么前面的偶数次可以用来做反复变化,最后一次将最小的正数变成负数即可。
贪心的思路,局部最优:让绝对值大的负数变为正数,当前数值达到最大,整体最优:整个数组和达到最大。
局部最优可以推出全局最优。
真正实施代码:
1 | int largestSumAfterKNegations(vector<int>& nums, int k) { |
时间复杂度 O (nlogn),即主要是排序消耗的时间;空间复杂度 O (1)
优化思路:
- 第一步:将数组按照绝对值大小从大到小排序,注意要按照绝对值的大小
- 第二步:从前向后遍历,遇到负数将其变为正数,同时 K–
- 第三步:如果 K 还大于 0,那么反复转变数值最小的元素,将 K 用完
- 第四步:求和
这里优化了判断当负数处理完之后判断是否有 0 的存在,直接反复处理最小的元素即可。
贪心周总结
股票问题:把一段时间的利润拆分成这几天每一天的利润。即用一天价格减去前一天的价格做差。
这样贪心的思路就是:只收集正利润,即上涨的利润。全局最优:得到最大利润

跳跃游戏 I:问题转换为覆盖范围,即每次跳跃取最大步数是这一步目前的最大覆盖范围。
局部最优:每次都取最大范围。
整体最优:整体最大覆盖范围是否能够到达终点。
跳跃游戏 II:当前最大覆盖范围:一步内可以到达的地方。如果当前最大覆盖范围没有到达终点,那么就需要再走一步,扩大覆盖范围。新走的一步也要使得覆盖范围最大,即保证下一步的覆盖范围最大。即在当前覆盖范围内可走的下标 i + nums [i] 就是走到下一步 i 的覆盖范围。
K 次取反之后最大化的数组和:局部最优:让绝对值最大的负数先变成正数。然后再让绝对值最小的正数变成负数。
加油站
题目:134
在一条环路上有 n 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
给定两个整数数组 gas 和 cost ,如果你可以按顺序绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1 。如果存在解,则 保证 它是 唯一 的。
思路:
每个加油站的剩余量 rest [i] 为 gas [i] - cost [i]。
i 从 0 开始累加 rest [i],和记为 curSum,一旦 curSum 小于零,说明 [0, i] 区间都不能作为起始位置,因为这个区间选择任何一个位置作为起点,到 i 这里都会断油,那么起始位置从 i+1 算起,再从 0 计算 curSum。
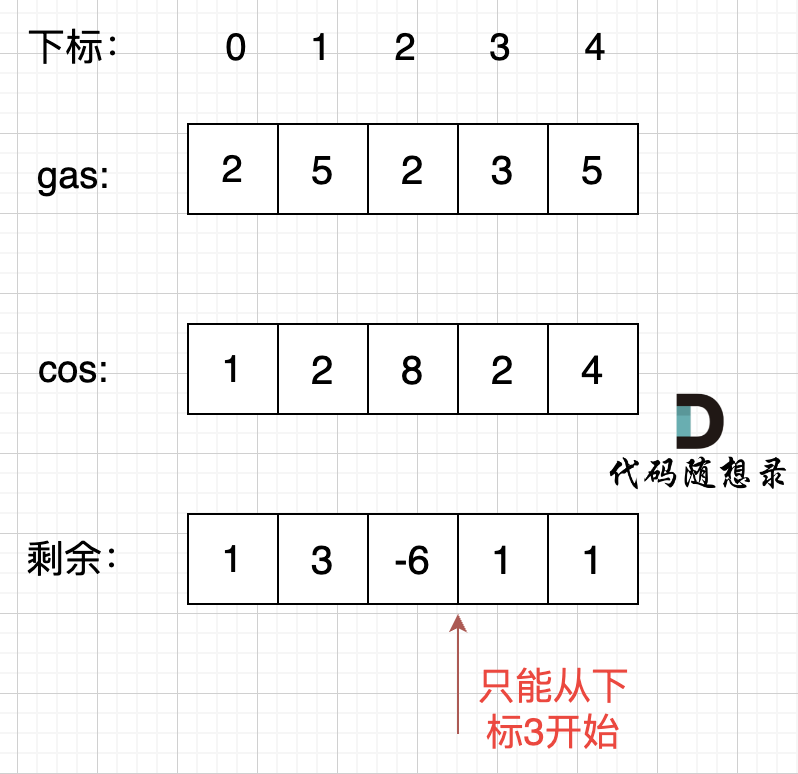
那么为什么一旦 [0,i] 区间和为负数,起始位置就可以是 i+1 呢,i+1 后面就不会出现更大的负数?
如果出现更大的负数,就是更新 i,那么起始位置又变成新的 i+1 了。
那有没有可能 [0,i] 区间 选某一个作为起点,累加到 i 这里 curSum 是不会小于零呢? 如图:
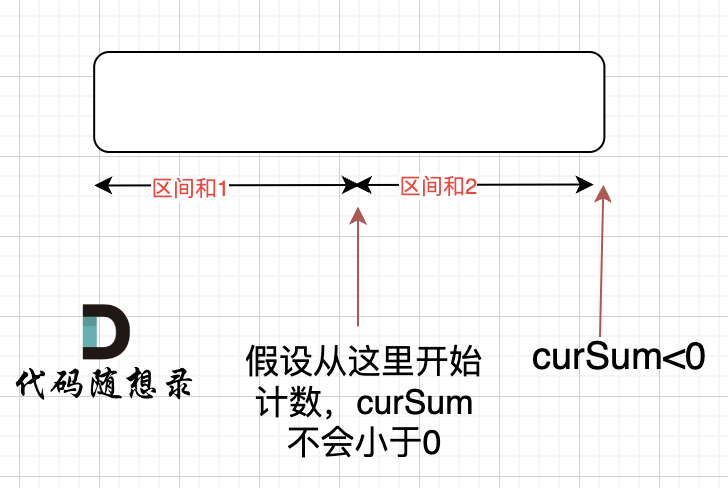
如果 curSum<0 说明 区间和 1 + 区间和 2 < 0, 那么 假设从上图中的位置开始计数 curSum 不会小于 0 的话,就是 区间和 2>0。
区间和 1 + 区间和 2 <0 同时 区间和 2>0,只能说明区间和 1 < 0, 那么就会从假设的箭头初就开始从新选择其实位置了。
那么局部最优:当前累加 rest [i] 的和 curSum 一旦小于 0,起始位置至少要是 i+1,因为从 i 之前开始一定不行。全局最优:找到可以跑一圈的起始位置。
1 | class Solution { |
时间复杂度 O (n),空间复杂度 O (1)
分发糖果
题目:135
思路:初始化时每个孩子至少一个糖果。
从前向后遍历,当左孩子小于右孩子时,右孩子糖果等于左孩子糖果 + 1;(那么如果左孩子大于右孩子呢?理论上应该是左孩子糖果等于右孩子 + 1,但是遍历顺序是从前向后,所以此时没办法确定右孩子的糖果数目;如果令左孩子糖果书 - 1,那么会影响前边的遍历结果。)从左向右保证:相邻的两个孩子,如果右边的分数高,那么右边的糖果比左边多一个
接着从后向前遍历,此时就能够根据右孩子糖果数确定左孩子糖果数,此时如果左孩子大于右孩子,那么此时左孩子有两个选择,一个选择是右孩子 + 1,另一个选择是上一步中求得的这个孩子应该有的糖果数。应该选择较大的,这样既能保证大于左边又能保证大于右边。
时间复杂度 O (n),空间复杂度 O (n)
采用了两次贪心的策略:
- 一次是从左到右遍历,只比较右边孩子评分比左边大的情况。从左向右保证:相邻的两个孩子,如果右边的分数高,那么右边的糖果比左边多一个
- 一次是从右到左遍历,只比较左边孩子评分比右边大的情况。从右向左保证,如果左边的分数高,左边的糖果比右边多一个
这样从局部最优推出了全局最优,即:相邻的孩子中,评分高的孩子获得更多的糖果。
1 | class Solution { |
柠檬水找零
题目:860
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
给你一个整数数组 bills ,其中 bills[i] 是第 i 位顾客付的账。如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
思路:
- 情况一:账单是 5,直接收下。
- 情况二:账单是 10,消耗一个 5,增加一个 10
- 情况三:账单是 20,优先消耗一个 10 和一个 5,如果不够,再消耗三个 5
账单是 20 的情况,为什么要优先消耗一个 10 和一个 5 呢?
因为美元 10 只能给账单 20 找零,而美元 5 可以给账单 10 和账单 20 找零,美元 5 更万能!
所以局部最优:遇到账单 20,优先消耗美元 10,完成本次找零。全局最优:完成全部账单的找零。
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (1)
根据身高重建队列
题目:406
假设有打乱顺序的一群人站成一个队列,数组 people 表示队列中一些人的属性(不一定按顺序)。每个 people[i] = [hi, ki] 表示第 i 个人的身高为 hi ,前面 正好 有 ki 个身高大于或等于 hi 的人。
请你重新构造并返回输入数组 people 所表示的队列。返回的队列应该格式化为数组 queue ,其中 queue[j] = [hj, kj] 是队列中第 j 个人的属性(queue[0] 是排在队列前面的人)。
思路:
遇到两个维度权衡的时候,一定要先确定一个维度,再确定另一个维度。
如果两个维度一起考虑一定会顾此失彼。
对于本题相信大家困惑的点是先确定 k 还是先确定 h 呢,也就是究竟先按 h 排序呢,还是先按照 k 排序呢?
如果按照 k 来从小到大排序,排完之后,会发现 k 的排列并不符合条件,身高也不符合条件,两个维度哪一个都没确定下来。
那么按照身高 h 来排序呢,身高一定是从大到小排(身高相同的话则 k 小的站前面,,后续根据 k 值选择插入位置,防止小的 k 值还不存在就插入大的 k 值下标),让高个子在前面。
此时我们可以确定一个维度了,就是身高,前面的节点一定都比本节点高!
那么只需要按照 k 为下标重新插入队列就可以了,为什么呢?
以图中 {5,2} 为例:

按照身高排序之后,优先按身高高的 people 的 k 来插入,后序插入节点也不会影响前面已经插入的节点,最终按照 k 的规则完成了队列。
所以在按照身高从大到小排序后:
局部最优:优先按身高高的 people 的 k 来插入。插入操作过后的 people 满足队列属性
全局最优:最后都做完插入操作,整个队列满足题目队列属性
例子:
排序完的 people: [[7,0], [7,1], [6,1], [5,0], [5,2],[4,4]]
插入的过程:
- 插入 [7,0]:[[7,0]]
- 插入 [7,1]:[[7,0],[7,1]]
- 插入 [6,1]:[[7,0],[6,1],[7,1]]
- 插入 [5,0]:[[5,0],[7,0],[6,1],[7,1]]
- 插入 [5,2]:[[5,0],[7,0],[5,2],[6,1],[7,1]]
- 插入 [4,4]:[[5,0],[7,0],[5,2],[6,1],[4,4],[7,1]]
时间复杂度 O (nlogn + n^2),后面的时间复杂度是指遍历一遍所有的元素,然后根据 k 选择插入位置
空间复杂度 O (n)
1 | class Solution { |
贪心周总结
加油站:这道题首先想要能够走完一圈,每一站的加油量减去消耗量之和(就是总油量要大于总消耗量),走完一圈一定是正的。
其次是判断起点的问题,将每一站的差值从第 0 站开始进行累加,当累加为负数时,说明起始位置到这一站之间都不能作为起点,因为不管是哪一个作为起点,到这里都会却油。所以必须从后面一站开始。接着重新进行累加,继续更新。
贪心的思想体现在:累加的差值如果小于 0,那么至少从下一个开始。
分发糖果:这个问题的关键在于:如果从左向右比,那么一定是根据前者才能更新后者,所以只能更新后者,更新后者的情况就是当后者评分大于前者时,此时后者应该比前者多 1 个。(为什么不能当前者评分大于后者时,更新前者为后者糖果数目 + 1 呢?因为此时后者的糖果数并不是最终结果,如果在后续操作中后者糖果发生改变,那么这一步对于前者的修改就是不正确的。)
在从左向右比之后,此时所有后者大于前者的人都已经更新。
接着需要从右向左进行比较,此时可以根据后者更新前者,具体更新逻辑为,如果前者的评分大于后者,那么前者的糖果数应该取上一步更新的糖果数和后者 + 1 中较大值。
贪心的思想体现在:从左向右:只要后者大于前者,那么后者就为前者 + 1;从右向左,如果前者大于后者,那么前者就必须比后者多。
买柠檬水找零:贪心的思想体现在,尽可能先使用 10 元进行找零,因为 10 元只能对于 20 元进行找零,而 5 元既可以对 10 元找零,也可以对 20 元找零。
根据身高重建队列:存在两个维度,应该先使得一个维度有序,然后再考虑另一个维度。
这里先按照身高从大到小排序(身高相同的话则 k 小的站前面),这样能够保证高个子在前面。
然后根据第二个维度 k 值,将其放入第 k 个下标对应的位置。
(为什么 k 小的站前面?主要是因为进行重新插入时,从前向后处理。如果先处理 K 大的,那么有可能对于一个队列来说超出目前队列的长度)
贪心体现在:k 值表示前面正好有 k 个大于或者等于这个身高的人。那么已经按照身高排序,然后按照身高从高向低处理,插入到第 k 个位置,至少能够保证前面有 k 个人大于或等于该身高。即使后续前面再插入新元素,新元素一定是比该身高低。(因为后处理的元素比先处理的元素身高低)
用最少数量的箭引爆气球
题目:452
有一些球形气球贴在一堵用 XY 平面表示的墙面上。墙面上的气球记录在整数数组 points ,其中 points[i] = [xstart, xend] 表示水平直径在 xstart 和 xend 之间的气球。你不知道气球的确切 y 坐标。
一支弓箭可以沿着 x 轴从不同点 完全垂直 地射出。在坐标 x 处射出一支箭,若有一个气球的直径的开始和结束坐标为 x``start,x``end, 且满足 xstart ≤ x ≤ x``end,则该气球会被 引爆 。可以射出的弓箭的数量 没有限制 。 弓箭一旦被射出之后,可以无限地前进。
给你一个数组 points ,返回引爆所有气球所必须射出的 最小 弓箭数 。
我的思路(存在缺陷):对于一个气球来说,想要引爆的射箭位置就是 [L, H],那么如果想要一次引爆多个气球,就需要从他们的交集位置射出,所以我的思路就是遍历所有气球位置,使得尽量从交集位置射出。
但是问题是:气球顺序会影响两个位置范围结合求子集的顺序,这样会使得
1 | [[3,9],[7,12],[3,8],[6,8],[9,10],[2,9],[0,9],[3,9],[0,6],[2,8]] |
比如上面的气球顺序,当 [7,12],[3,8] 相遇,那么子集范围就确定为 [7,8],不能达到最小箭的数目
这里明显是 6 可以解决除了最后一个所有的气球,但是如果采用上面的思路,就需要 3 个箭头。
但是如果排序之后再使用上面算法,可以通过,但是时间复杂度是 O (max (nlogn, n^2))
作者的思路:
局部最优:当气球出现重叠,一起射,所用弓箭最少。全局最优:把所有气球射爆所用弓箭最少。
如果把气球排序之后,从前到后遍历气球,被射过的气球仅仅跳过就行了,没有必要让气球数组 remove 气球,只要记录一下箭的数量就可以了。为了让气球尽可能的重叠,需要对数组进行排序。
如果气球重叠了,重叠气球中右边边界的最小值 之前的区间一定需要一个弓箭。
以题目示例: [[10,16],[2,8],[1,6],[7,12]] 为例,如图:(方便起见,已经排序)

1 | class Solution { |
时间复杂度 O (nlogn),快速排序;空间复杂度 O (1)
无重叠区间
题目:435
给定一个区间的集合 intervals ,其中 intervals[i] = [starti, endi] 。返回 需要移除区间的最小数量,使剩余区间互不重叠 。
思路:贪心:发现重叠的区间就移除较大的区间
与上一题一样,先进行排序,然后依次比较相邻两个区间:已知后者的左端点一定大于等于前者的左端点,如果后者的左端点大于等于前者的右端点,说明后者整体区间在前者后面,无重叠;否则说明存在交集,应该将右边界更大的删除,以更小的右边界作为切割点。
时间复杂度 O (nlogn),快速排序;空间复杂度 O (1)
1 | class Solution { |
另一种思路:按照右边界排序,从左至右计算不重叠的区间个数,总区间个数减去不重叠的区间个数就是需要移除的区间个数。
这里记录非交叉区间的个数还是有技巧的,如图:

区间,1,2,3,4,5,6 都按照右边界排好序。
当确定区间 1 和 区间 2 重叠后,如何确定是否与 区间 3 也重贴呢?
就是取 区间 1 和 区间 2 右边界的最小值,因为这个最小值之前的部分一定是 区间 1 和区间 2 的重合部分,如果这个最小值也触达到区间 3,那么说明 区间 1,2,3 都是重合的。
接下来就是找大于区间 1 结束位置的区间,是从区间 4 开始。那有同学问了为什么不从区间 5 开始?别忘了已经是按照右边界排序的了。
区间 4 结束之后,再找到区间 6,所以一共记录非交叉区间的个数是三个。
总共区间个数为 6,减去非交叉区间的个数 3。移除区间的最小数量就是 3。
划分字母区间
题目:763
思路 1:遍历所有元素,对于每一个元素求其最后一次出现的下标作为 max_end,一个分区的长度以内部所有元素中最大的 max_end 作为分区右边界。
1 | int FindMaxend(const string &s, char c) { |
时间复杂度 O (n^2),遍历所有字符,每次在循环中查找当前字符出现的最后位置;空间复杂度 O (n)。这里的 n 是进行函数调用栈的空间消耗
思路 2:与上面基本一致,但是作者首先使用一个 hash 表计算出所有元素的最后一次的下标,这个时间复杂度为 O (n);
然后一个细节是当 i == max_end 时就可以记录当前分区长度了,这样就不需要循环结束之再统计最后一个分区的长度
1 | vector<int> partitionLabels(string s) { |
时间复杂度 O (n);空间复杂度 O (1),固定 hash 表的长度
思路 3:每个字符都有一个区间 [start, end],先按照左边界进行排序,然后求重叠区间的合并区间即可。
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (n)
合并区间
题目:56
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
思路:这道题与 “用最少的数量的箭引爆气球” 和” 无重叠区间 “类似,都是先排序使得左右边界中的一个边界有序,然后根据另一个边界判断是否出现重叠。
这道题出现重叠时需要将以更小的左边界和更大的右边界合并两个区间。
以左边界排序,然后根据右边界的情况判断是否重叠:已知排序之后前者的左边界 小于等于 后者的左边界,如果后者的左边界大于(注意这里等于也是重叠)前者的右边界,说明后者整体在前者的后面,无重叠现象,此时不需要处理;否则,就应该以前者的左边界作为新区间的左边界,以 max (前者的右边界,后者的右边界) 作为新区间的右边界。
时间复杂度 O (nlogn),快速排序的时间;空间复杂度 O (n),需要一个 ans 数组
1 | class Solution { |
作者的思路:与上面基本一致,不一样的是一点细节:作者直接把第一个区间加入答案中,当发现重叠时,就直接在答案的最后一个区间上进行修改;无重叠的话就直接把当前区间加入答案数组。等待更新
而我的思路是比较连续两个区间,如果出现重叠区间,就把合并后的区间赋给后者,然后继续参与比较;只有当遇到不重叠时,才把前者加入答案(也就是之前几个区间合并后的结果)。这样做的坏处就是最后一个区间需要在循环结束之后再添加。
贪心周总结
用最少的箭引爆气球、无重叠区间、合并区间:这三道题都类似,第一步就是先使得一个维度有序,这里采用的都是使得左边界从小到大排列;然后从前到后根据比较相邻两个区间的右边界判断是否出现重叠;最后根据重叠与否做出不同的行为。
划分字母区间:尽量保证一个分区的右边界为区间内元素最后一次出现的位置。另外可以表示出每个字符的左右边界,合并边界区间。
这道题给我的收获是:如果在处理一个循环时需要根据原始数据进行某些操作,考虑是否可以提前进行这些操作。
也就是在 n 循环中做时间复杂度为 n 的操作,可以优化为先做时间复杂度为 n 的操作得到需要的数据,然后再进行 n 循环。
单调递增的数字
题目:738
思路:贪心的思路:一旦出现了非单调递增的情况,即 strNum [i - 1] > strNum [i],那么最接近的单调递增整数应该是令 strNum [i - 1]–,令 strNum [i] 以及后面的数字全都等于 9.
从前向后遍历还是从后向前遍历:
(1)从前向后遍历:遇到 strNum [i - 1] > strNum [i] 的情况,让 strNum [i - 1] 减一,但此时如果 strNum [i - 1] 减一了,可能又小于 strNum [i - 2]。
采用两次遍历的方法:第一次遍历从前向后,如果单调递增,则不做处理;如果出现非递增情况,令前一位减去 1,后面所有位置为 9。
由于减去 1 之后有可能会使得小于更前面的数字,因此需要第二次遍历,从后向前遍历,当前位置数字如果小于前面的,应该使得当前数字为 9,另前一位数字减去 1.
使用两个栈,一个栈保存源数据,一个栈保存结果数据。
时间复杂度 O (n),包括使用栈保存每一位数字、遍历栈中每一位数字求存储结果每一位的栈、遍历结果栈得到最终答案;
空间复杂度 O (n)
(2) 从后向前遍历:只要前者大于后者,就令后者以及后面全都为 9,前者减去 1
1 | class Solution { |
时间复杂度 O (n);空间复杂度 O (n-)
监控二叉树
题目:968
思路:摄像头可以覆盖上中下三层,如果把摄像头放在叶子节点上,就浪费的一层的覆盖。
所以把摄像头放在叶子节点的父节点位置,才能充分利用摄像头的覆盖面积。
为什么不从头结点开始看起呢,为啥要从叶子节点看呢?
因为头结点放不放摄像头也就省下一个摄像头, 叶子节点放不放摄像头省下了的摄像头数量是指数阶别的。
所以我们要从下往上看,局部最优:让叶子节点的父节点安摄像头,所用摄像头最少,整体最优:全部摄像头数量所用最少!
所以确定采用后续遍历。
接着是计算摄像头个数:递归的处理就是返回结点的状态。
分别有三个数字来表示结点状态:
- 0:该节点无覆盖
- 1:本节点有摄像头
- 2:本节点有覆盖
因为在遍历树的过程中,就会遇到空节点,那么问题来了,空节点究竟是哪一种状态呢? 空节点表示无覆盖? 表示有摄像头?还是有覆盖呢?
回归本质,为了让摄像头数量最少,我们要尽量让叶子节点的父节点安装摄像头,这样才能摄像头的数量最少。
那么空节点不能是无覆盖的状态,这样叶子节点就要放摄像头了,空节点也不能是有摄像头的状态,这样叶子节点的父节点就没有必要放摄像头了,而是可以把摄像头放在叶子节点的爷爷节点上。
所以空节点的状态只能是有覆盖,这样就可以在叶子节点的父节点放摄像头了
主要有如下四类情况:
- 情况 1:左右节点都有覆盖
左孩子有覆盖,右孩子有覆盖,那么此时中间节点应该就是无覆盖的状态了。
- 情况 2:左右节点至少有一个无覆盖的情况
如果是以下情况,则中间节点(父节点)应该放摄像头:
- left == 0 && right == 0 左右节点无覆盖
- left == 1 && right == 0 左节点有摄像头,右节点无覆盖
- left == 0 && right == 1 左节点有无覆盖,右节点摄像头
- left == 0 && right == 2 左节点无覆盖,右节点覆盖
- left == 2 && right == 0 左节点覆盖,右节点无覆盖
这个不难理解,毕竟有一个孩子没有覆盖,父节点就应该放摄像头。
此时摄像头的数量要加一,并且 return 1,代表中间节点放摄像头。
- 情况 3:左右节点至少有一个有摄像头
如果是以下情况,其实就是 左右孩子节点有一个有摄像头了,那么其父节点就应该是 2(覆盖的状态)
left == 1 && right == 2 左节点有摄像头,右节点有覆盖
left == 2 && right == 1 左节点有覆盖,右节点有摄像头
left == 1 && right == 1 左右节点都有摄像头
情况 4:头结点没有覆盖
以上都处理完了,递归结束之后,可能头结点 还有一个无覆盖的情况。
时间复杂度 O (n)
空间复杂度 O (n),递归栈消耗时间
思路 2:贪心:一个摄像头可以覆盖上中下三层,放在中间覆盖范围最大。尽量让叶子节点的父节点安装摄像头
采用后序遍历处理:如果头节点不妨也就省下一个,如果叶子不放省下指数级别。
使用 3 种状态表示结点:
- val 的值为 0 表示未被监控
- 1 表示已经被监控
- 2 表示此位置放置监控。放置监控的位置本身表示被监控
1. 递归的参数和返回值:参数是当前子树根节点,和父节点;返回值是左右字数监控个数
2. 递归的终止:遇到空结点
3. 处理逻辑:首先递归左右孩子。接着:如果当前结点是叶子结点,则在父亲结点安装监控,并令当前结点的状态为 1. 返回 0
最后:根据当前状态和左右孩子状态处理:详细参考代码:
1 | /** |
(这里给出思考过程:如果空结点不进入递归,那么分四种情况:
1. 当前结点没有孩子,即叶子结点:此时应该令父节点安装监控为状态 2,当前结点为状态 1,返回 0;
2. 当前结点只有左孩子:递归左子树得到左子树监控数目,然后根据当前结点的状态做处理(3 种情况);
3. 当前结点只有右孩子:同理
4. 当前结点有左右孩子:此时需要递归左右子树获得监控数目,然后再根据当前结点状态做处理
2、3、4 这些情况代码重复,因此选择令空结点进入递归,并且返回 0,这样就能使用 left 和 right 接收左右子树监控数目。